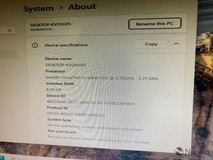
当我们评定一款显卡性能如何的时候,一般从核心频率、流处理器数量、显存、位宽、功耗等角度去衡量,但是在它们的背后,隐藏着真正的大boss,那就是显卡架构。无论英伟达还是AMD,每一代显卡都会及时对架构进行更新,以追求性能的再突破,英伟达对于架构的命名方式也很有趣,英伟达则喜欢用科学发展史上的伟人来命名,接下来让我们看看都有哪些吧。
Kelvin(开尔文)
Kelvin于2001年发布,是NVIDIA千禧年的第一个新的GPU微架构。最初的XBOX游戏机使用带有Kelvin微架构的NV2A GPU。GeForce 3 和 GeForce 4 系列 GPU也以Kelvin微架构发布。
Rankine(兰金)
Rankine是2003年发布的Kelvin的后续产品,用于NVIDIA GPU的GeForce 5系列。Rankine支持顶点和片段程序,并将VRAM大小增加到256MB。
Curie(居里)
Curie 是 GeForce 6和7系列GPU使用的微架构,于2004年作为Rankine的继任者发布。Curie将VRAM的数量翻了一倍,达到512MB,并且是支持PureVideo视频解码的第一代NVIDIA GPU。
Tesla(特斯拉)
Tesla GPU微架构于2006年作为Curie的继任者发布,为NVIDIA的GPU产品线引入了几项重要变化。除了作为GeForce 8,9,100,200和300系列GPU使用的架构外,Tesla还被Quadro系列GPU用于图形处理以外的用例。
Tesla既是GPU微架构的名称,也是NVIDIA GPU的产品线名称。2020年,NVIDIA决定停止使用Tesla的名字,以避免与流行的电动汽车品牌混淆。
Fermi(费米)
Fermi是Tesla特斯拉的继任者,于2010年发布。Fermi引入了许多增强功能,包括:
支持 512 个 CUDA 内核;64KB RAM 和分区 L1 缓存/共享内存的能力;支持纠错码 (ECC)。
Kepler(开普勒)
Kepler GPU微架构作为Fermi 2012的继任者发布。与费米相比,关键改进包括:
一种新的流式多处理器架构,称为 SMX;
支持 TXAA(一种抗锯齿方法);
CUDA 核心数增加到 1536 个;
更低的功耗;
支持通过 GPU 加速自动超频;
支持 GPUDirect,允许 GPU (在同一台计算机中或通过网络相互访问) 在不访问 CPU 的情况下进行通信。
Maxwell(麦克斯韦尔)
Maxwell,于2014年发布,是Fermi的继任者。第一代Maxwell GPU比费米具有以下优势:
由于与控制逻辑分区、时钟门控、指令调度和工作负载平衡相关的增强功能,多处理器效率更高;
每个流式多处理器上有 64KB 的专用共享内存;
本机共享内存原子操作,与费米使用的锁定/解锁范例相比,可提供性能改进动态并行度支持。
Pascal(帕斯卡)
Pascal于2016年接替Maxwell。Pascal(帕斯卡)NVIDIA GPU微架构提供了对Maxwell的改进,如:
支持 NVLink 通信,与 PCIe 相比,可提供显著的速度优势;
高带宽内存 2 (HBM2) - 4096 位内存总线,提供 720 GB 的内存带宽;
计算抢占;动态负载均衡,可优化 GPU 资源利用率。
Volta(伏特)
Volta是2017年发布的一个有点独特的微架构迭代。Volta GPU严格针对专业级市场。Volta也是第一个使用Tensor Cores的微架构。Tensor Cores(张量核心)是一种较新型的处理核心,用于执行专门的数学计算。Tensor Cores执行矩阵运算,以支持AI和深度学习应用。
Turing(图灵)
Turing于2018年发布,支持Tensor Cores,并首次加入RT Core。Turing是NVIDIA流行的Quadro RTX和GeForce RTX系列GPU使用的微架构。GPU 支持实时光线追踪,对于虚拟现实 (VR) 等计算量大的应用至关重要。
Ampere(安培)
Ampere架构旨在进一步提升光线追踪运算、高性能计算(HPC)和AI运算的能力。Ampere中的增强功能包括第3代NVLink和Tensor Core,结构稀疏性(将不需要的参数转换为零以实现AI模型训练),第二代光线追踪内核,多实例GPU(MIG)等。