破圈式的发展,让 DeepSeek 的热度飙升。但由此引发的海量并发请求也导致负载严重过载,让满心的期盼,却得到了:「服务器繁忙,请稍后重试」这样冷冰冰的回复。
作为行业领先云与 AI 服务商,火山引擎依托字节跳动的技术积累和经验沉淀,在保证原版 DeepSeek 模型效果的同时,决定给系统承载力、推理速度和部署安全这几个核心要点「上上强度」,还你一个永不繁忙、安全无忧的 DeepSeek。
全网最高承载力:500万初始TPM,告别服务器繁忙
「高并发」是企业用户在应用 DeepSeek 这款现象级大模型重要需求,为了更好地助力企业、开发者们在业务场景中应用 DeepSeek 全系列模型和豆包大模型1.5,火山引擎将原本80万的初始 TPM,再次提高至500万,全网最高!
我们对比了目前主要 DeepSeek 三方服务商的 TPM 规模,我们期望越来越高的 TPM 规模,能够让客户低门槛地做出更有深度、更大并发的创新应用。

此外,除了500万的初始 TPM,火山引擎还提供全网首家「50亿初始离线 TPD 配额」,可满足企业信息打标以及其他大使用量的离线场景。
推理速度更快:30msTPOT超低延迟
TPOT 代表的是吐字间隔,为了让 DeepSeek 更快、更准确地与用户交互,火山引擎不断完善推理层性能优化,将其降低到接近30ms,并将持续优化,未来将 TPOT 进一步压低至稳定15ms~30ms区间,成为国内最低延迟的大规模 DeepSeek-R1推理服务,帮助用户畅享流畅的交互体验。
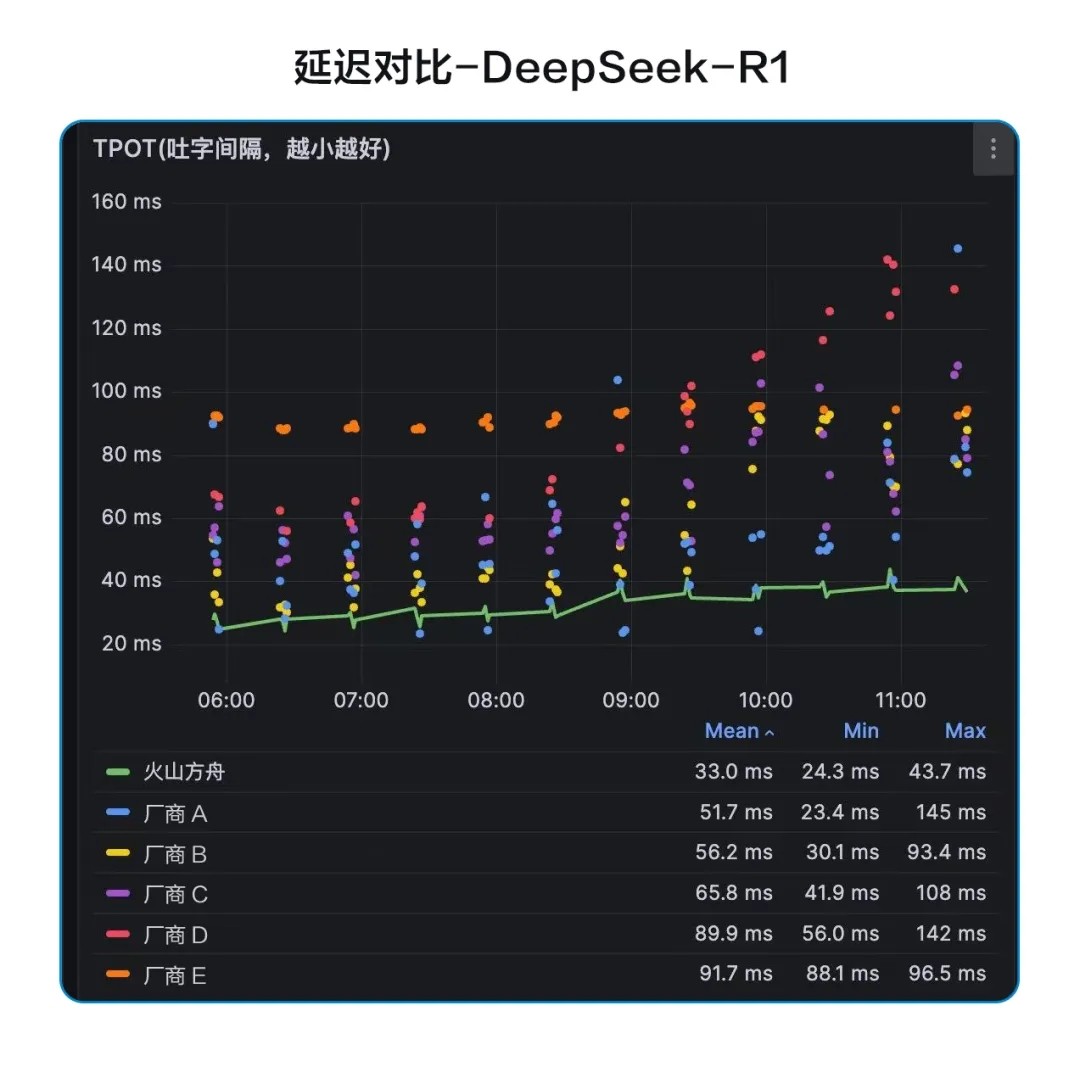
通过全栈自研的推理引擎,火山引擎在 DeepSeek 系列模型上进行了算子层、推理层、调度层的深度优化,与此同时,火山方舟还提供了完善的大模型调用监控与告警能力,充分保障模型应用的高流量、低延迟和稳定性。
深度思考+联网搜索,让模型回答实时且精准
联网搜索能力解决了大模型「将故事当新闻」的通病,可以让 DeepSeek 获取最新最全网络资讯,提升回答的时效性和准确度。
不过,如果联网搜索能力仅提供是否联网的开关,用户就不能修改中间的联网配置细节,无法按照需求进行个性化定制。而火山方舟上,用户可以自行配置内容源、引用条数,并稍后可进行联网意图、改写模块等多项高级配置。将你对联网的个性化需求充分满足,适合企业用户灵活、丰富的应用场景。
此外,在联网内容上,提供头条图文和抖音百科海量优质实时内容,帮助搜索内容更丰富地呈现。
多重解法,让各类安全问题退退退
关于大模型「安全性」的话题,始终是业界关注的焦点之一,内容安全攻击、提示词注入攻击引导 AI 应用输出不当回答;DDoS 攻击通过消耗计算资源,降低 AI 应用可用性;而模型和 Prompt、隐私和商业敏感数据泄漏等也将引发企业纠纷。面对大模型 AI 应用的多种安全威胁,火山引擎通过多种解法,为企业 AI 应用「穿上盔甲」,杜绝安全隐患,让各类安全问题「退!退!退!」
火山方舟采用加密技术及严格访问控制策略,杜绝训练数据、隐私和商业敏感数据及模型 Prompt 泄漏;通过火山引擎 PCC 私密云,可进一步在端到端场景下保障数据安全。
同时,火山引擎大模型安全防火墙可有效拦截针对大模型的 DDoS 攻击、提示词攻击,并识别不合规内容,在针对 DeepSeek R1和 V3模型安全性测试中,可将提示词注入攻击成功率降低到1%以下。
针对各种推理和训练场景,火山引擎提供多种接入 DeepSeek 方式,并特别提供限时5折优惠(截止到2月18日24点),助力企业畅享 DeepSeek 模型!

本文属于原创文章,如若转载,请注明来源:在火山引擎用DeepSeek,更稳更快:500万TPM、30ms低延迟https://news.zol.com.cn/949/9491839.html