企查查是一家专注于企业信用信息服务的科技公司,依托大数据、人工智能等技术,为企业提供全面、准确、及时的企业信用信息,助力企业降本增效、风险防控。2023 年 5 月,企查查正式发布全球首款商查大模型——“知彼阿尔法”。该模型基于企查查覆盖的全球企业信用数据进行训练,可以为司法、金融、风控、政务等人士提供多维度数据服务。
从 MySQL 到 TiDB 的升级之路
数据是企查查业务的核心,需要对海量数据进行清洗、分析、挖掘,才能充分释放数据价值。在引入 TiDB 之前,企查查使用 MySQL 数据库。MySQL 是一款受欢迎的开源关系型数据库,但存在单机性能瓶颈。当数据量达到一定规模后,垂直扩容只能有限提升性能,在高并发写入和复杂 SQL 查询等场景下,性能会受到单机性能的限制。
由于 MySQL 是单机数据库,在业务不中断的情况下,只能采用热备。但是,随着数据量的增长,MySQL 的热备操作会变得越来越慢,对数据库的性能产生较大影响。此外,热备数据的恢复速度也较慢。在企查查的数据流向中,爬虫采集到的数据需要先存储到数据库中,然后再由 Flink 进行清洗。由于 MySQL 不支持将数据直接投递到 Flink,因此需要通过 Flink 来读写数据库,这对 MySQL 库产生了较大的压力。
2019 年底,企查查通过 TiDB 社区接触到 TiDB,并对其产生了浓厚的兴趣。经过对比选型测试,企查查选择了 TiDB 数据库,结合 Flink 场景的需求,构建了 Flink+TiDB 的实时数仓框架,应用于企查查数据中台。企查查选择 TiDB 的主要原因有:
切换到 TiDB 几乎无任何学习成本
因为 MySQL 存在的诸多问题,企查查迫切需要寻找一种兼容 MySQL 协议、且能解决上述问题的数据库。TiDB 在 MySQL 兼容性方面表现出色,能够兼容绝大多数 MySQL 语法和函数,包括 MySQL 生态的相关工具也都默认支持。此外,TiDB 在使用体验上与 MySQL 几乎没有差异,对于企查查这些 MySQL 基础的 DBA 来说,切换到 TiDB 几乎不需要学习成本,非常亲切。
原生分布式架构带来明显优势
在兼容 MySQL 协议的前提下,企查查需要一款能灵活水平扩展的分布式数据库满足业务发展的要求。企查查当时对分库分表类的分布式数据库进行了对比测试,发现对应用的开发侵入很大,且扩展性受限。TiDB 采用原生分布式数据库架构,基于 Spanner 和 F1 的论文设计。TiDB 的存储和计算分离,无中心化节点,支持任意扩缩容,支持分布式事务。此外,TiDB 的数据存储基于 Raft 共识算法,数据分片无需业务事先规划分片键,默认 3 个副本,保证了数据的高可用。TiDB 集群中的每个组件都做到了高可用设计,保证了服务的高可用。
周边工具完善
TiDB 的周边工具非常优秀,尤其是监控体系。TiDB 的监控体系采用了 Prometheus + Grafana + Alertmanager 等通用组件设计,这使得 TiDB 的监控体系能够无缝融入到企查查企业的监控告警体系中,非常方便。此外,TiDB 的监控体系非常全面,覆盖了系统运行中的各个环节,便于排查问题。TiDB 的上下游数据迁移和同步工具也比较成熟,特别是 TiCDC 工具。TiCDC 支持将 TiDB 中的数据同步到 Kafka 中,且支持 commitTS 的特性,保证了数据的一致性。TiDB 的备份和恢复工具也比较全面,支持逻辑备份(dumpling)和物理备份(BR),且不需要中断业务。在备份过程中,TiDB 可根据分布式节点的能力并行执行备份任务,效率相较 MySQL 单机备份大幅提升。
开源社区活跃
TiDB 的社区论坛非常活跃,企查查提的问题很快就会得到其他成员的回复。社区每隔几分钟就有人提出问题或回复问题。此外,还有许多技术爱好者撰写了博客和技术文章,这对企查查日常解决 TiDB 技术问题非常有帮助。企查查还参加了 TiDB 社区的线下活动。大家踊跃发言,分享使用 TiDB 过程中的经验和遇到的问题。TiDB 社区组织者也能很好地记录问题并采纳开发者的建议。这种开放透明的社区互动,让企查查感到使用 TiDB 很放心。
大数据生态友好
业务写入到数据库中的数据需要经过 Flink 进行清洗。TiDB 大数据的开源生态协同比较好,这也为企查查使用 TiCDC 提供了便利。通过 TiCDC 将 TiDB 的数据同步到 kafka 中,一方面方便 Flink 进行清洗;另一方面,其他下游的数据平台可以从 kafka 中消费数据,方便灵活。
TiDB 在数据中台系统的应用
TiDB 应用于企查查数据中台系统,覆盖了从数据采集到数据清洗整个流程,提供数据的存储和查询。企查查将原来的 20 多套 MySQL 数据库,替换成现在的 2 套 TiDB 集群。在数据清洗流程中,企查查使用 TiDB 自带的数据同步工具 TiCDC 将数据同步到下游其他的数据库和 kafka 中。目前,同步的表累计近千张。数据采集到数据清洗的数据流转,则是通过 TiCDC 捕捉变更数据同步到 Kafka 中实现的。此外,企查查使用了 TiCDC 中的 CommitTs 特性,通过数据在下游更新前的乐观锁控制,保证数据的一致性。
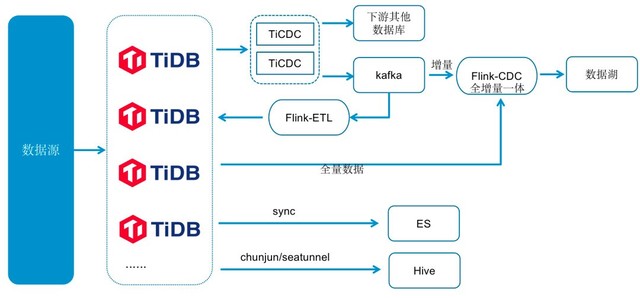
企查查数据中台系统逻辑示意图
TiDB 数据入湖使用了自研的 Flink Hybird Source。全量分片数据通过查询 TiDB 获取,增量数据通过消费 TiCDC 推送到 Kafka 的 Changelog 获取,准实时(分钟级)写入到 数据湖 Iceberg 中。Flink Hybird Source 支持全量、增量、和全增量一体三种数据同步模式。
企查查将 TiDB 的部分数据同步到 ES 系统中,为 ES 系统提供数据来源,供一些检索场景的应用使用。对于离线数据,企查查使用 Chunjun/Seatunnel 同步工具将其同步到 Hive 离线数据平台中,供下游的离线数据平台跑批。目前,企查查正在调研 TiFlash 的功能,计划今年将部分复杂的离线查询从 Hive 迁移到 TiDB 中,直接从 TiDB 中查询,以减少数据在多个数据栈中流转,进一步提升数据的实时性。
应用收益
数据价值在线化
TiDB 集群的分布式读写能力远超 MySQL,无论是从源端的爬虫写入 TiDB,还是 Flink 清洗后的数据写入,TiDB 都能够满足业务需求。结合 Flink 的实时计算能力,TiDB 可以保证数据的实时性。此外,TiDB 各节点并行读取数据的能力,大大提升了数据的分发查询能力,让数据价值得以在线化。
数据流转效率提升
TiDB 与上下游的数据生态兼容性良好,在接入端支持标准的 JDBC 写入,源端的数据可以直接写入到 TiDB,就像写 MySQL 一样简单。在出口端,TiDB 既可以通过 TiCDC 将数据分发到下游的 Kafka,并通过 CommitTS 特性保证业务数据的一致性,也可以通过标准接口将数据同步到下游的大数据平台,提高了企业数据的流转效率,盘活了数据资产。
Resource Control 满足不同业务的多租户需求
TiDB 7.1 版本引入了 Resource Control(资源管控)特性,企查查迅速升级到该版本。在升级后,企查查对查询平台中的正常程序账号不进行资源管控,以保证其资源得到保障;非程序账号进行部分资源管控,以防止其过多的消耗资源影响正常程序账号的查询效率。这样,企查查将不同类型的业务整合到一个 TiDB 集群中,提升了资源利用率,降低了 30% 的投入成本。此外,TiDB 的资源管控功能提供了多视角的监控,可以清晰地了解各个业务模块的资源使用情况。
本文属于原创文章,如若转载,请注明来源:数据价值在线化,TiDB 在企查查数据中台的应用https://news.zol.com.cn/856/8569016.html