据悉,昇思MindSpore开源社区将于 2025 年 12 月 25日在杭州举办昇思人工智能框架峰会。本次峰会将展示昇思亲和超节点技术创新点。面向本次大会的昇思人工智能框架技术发展与行业实践论坛,本文基本昇思AI框架技术发展实践,就AI框架共有的优化器并行相关技术进行探讨。
大模型训练中,随着模型参数向万亿级迈进,显存压力呈指数级增长,因此高效地利用显存,是训练能否有效进行的关键因素。为此,业界发展出多种“以通信换显存”的并行策略——其中最主流的是DeepSpeed Zero(ZeRO)、Megatron FSDP(Fully Sharded Data Parallel)。这些技术看似不同,实则都是将权重在dp(data parallel)维度进一步切分,以通信换显存。
昇思MindSpore的优化器并行方案于2020提出并将其实现开源,早于DeepSpeed Zero和Megatron FSDP,且Pytorch的原生并行库Titan提出的FSDP方案采用了与昇思MindSpore的优化器并行完全相同的方案。 本文将深入剖析这些技术,并揭示一个常被忽略的关键问题:“权重副本”到底需不需要?
Zero的深入剖析
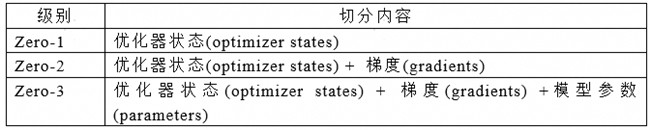
DeepSpeed提出Zero概念时,就对权重、梯度、优化器状态的分级切分给了严格的定义,如下表如下:
表1. Zero切分的定义
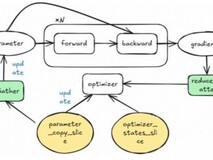
根据Zero分级切分定义,其形成的切分效果如下图所示:
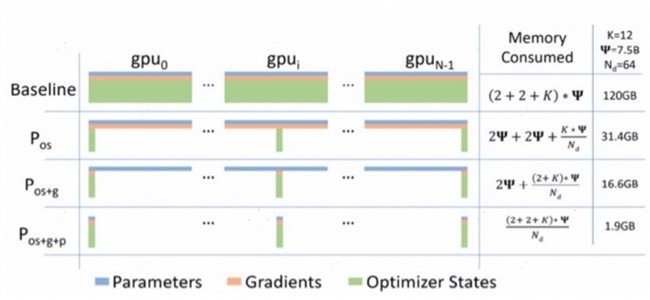
图1. Zero的切分效果
Zero的切分是针对模型的优化器状态、梯度、模型参数这3份静态显存进行切分,但这里存在一个隐藏问题:如果只切分优化器状态而不切权重,那更新时用哪个权重?实际上,还有一个“权重副本”(parameter copy) 需要参与计算。因此模型静态显存应为优化器状态、梯度、模型参数和权重副本4份,进而更新Zero的定义如下表:
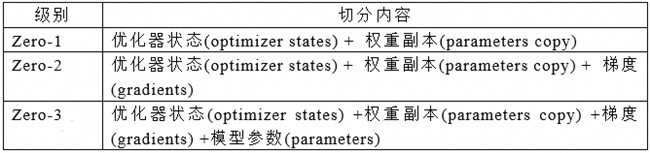
表2. Zero切分的更新定义
Zero-1的实现切分了优化器状态和权重副本,其模型的前向与反向在梯度累加场景下会执行N次(N为梯度累加次数),但AllGather与ReduceScatter只执行一次,其流程如图2所示:
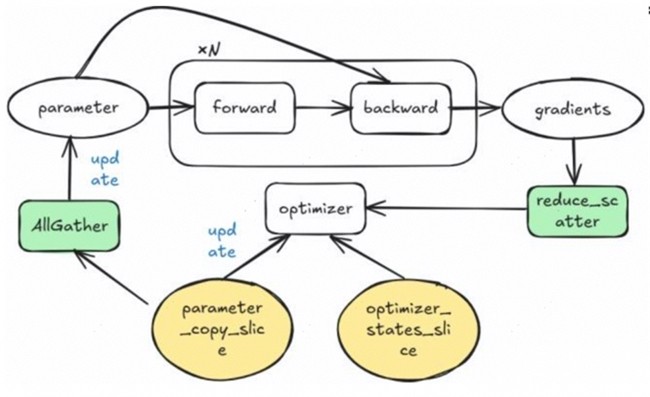
图2. Zero-1的流程
Zero-2对权重副本、优化器状态、梯度都进行了切分,其流程图如图3所示。为了能够切分梯度,在梯度累加前,先对反向出来的梯度执行一次ReduceScatter,那么这个ReduceScatter要执行N次,这样为了节省梯度参数的显存,引入了过量的ReduceScatter开销,因此在实际大模型训练中含梯度累加的场景,一般仅使用Zero-1。
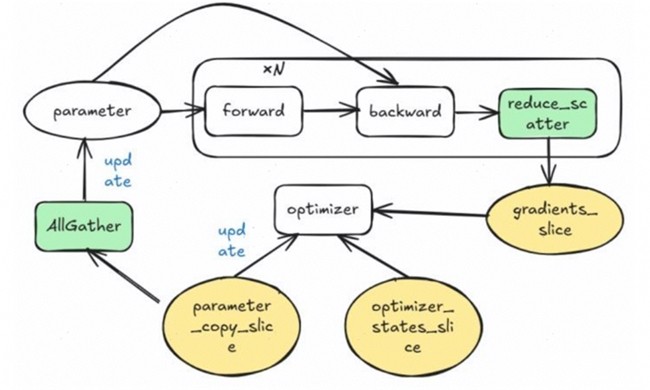
图3. Zero-2的流程
Zero-3对所有静态显存都进行了切分,其流程图如图4所示。为了除低显存在前反向开始计算前都会进行AllGather操作,引入了巨大的通信开销,同样在大模型训练的梯度累加场景一般是不可接受的。
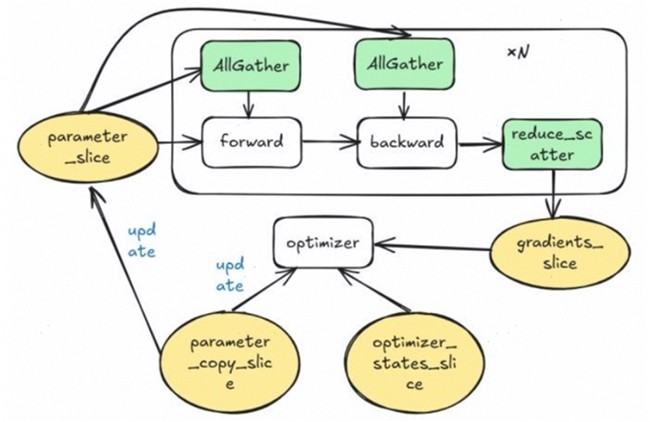
图4. Zero-3的流程
昇思MindSpore的优化器并行方案:去权重副本,更简洁
昇思MindSpore的优化器并行方案自2020年起就采用了一种无需权重副本的方案,其核心思路是“要切分优化器状态,就必须要切权重本身”。模型的静态显存可分优化器状态:直接切分到dp域,权重:随优化器状态切分,梯度:权在梯度累加时才分配静态显存。昇思MindSpore优化器并行Zero的方案通过表3给出。
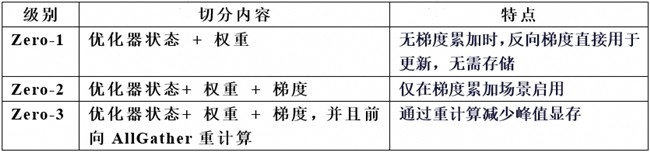
表3. 昇思MindSpore优化器并行Zero切分的定义
昇思MindSpore优化器并行Zero-1的流程只切分优化器状态与权重,分为非梯度累加与梯度累加2个场景,其中非梯度累加流程如图5所示,梯度累加流程如图6所示。在非梯度累加场景,去掉了梯度的静态显存,因此显存利用是明显优于DeepSpeed原版的。
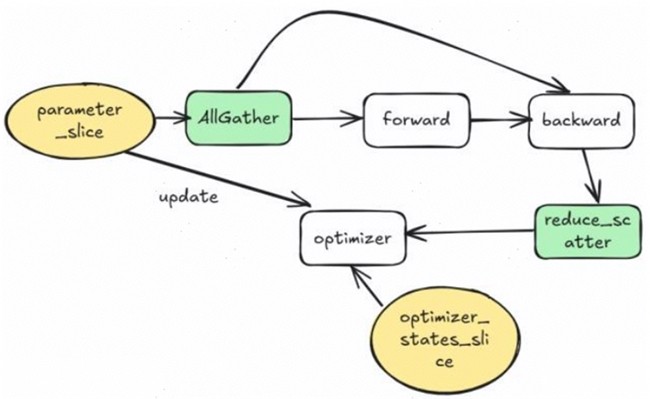
图5. 昇思MindSpore优化器并行Zero-1非梯度累加场景的流程
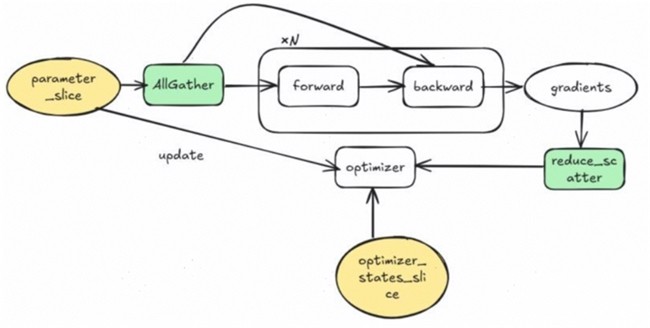
图6. 昇思MindSpore优化器并行Zero-1梯度累加场景的流程
昇思MindSpore优化器并行Zero-2的流程与DeepSpeed/Megatron的实现没有本质区别,如图7所示。
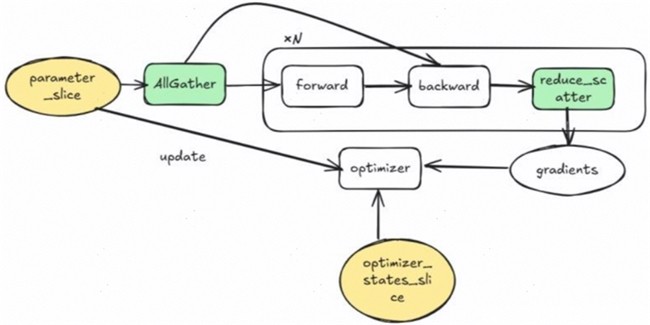
图7. 昇思MindSpore优化器并行Zero-2的流程
昇思MindSpore优化器并行Zero-3的流程与DeepSpeed/Megatron的实现也没有本质区别,给反向的AllGather通过对前向AllGather的重计算来实现,如图8所示。
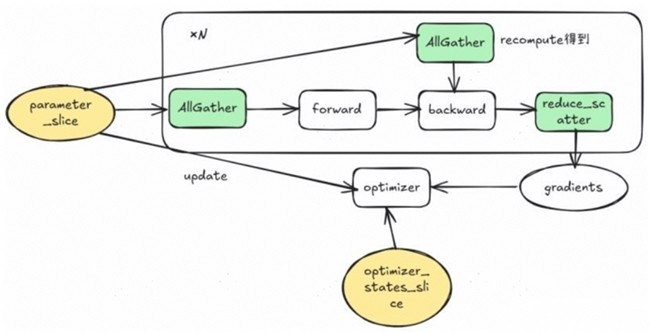
图8. 昇思MindSpore优化器并行Zero-3的流程
名字只是表象,思想才是核心。昇思MindSpore的优化器并行方案相较于DeepSpeed和Megaron方案有以下2大优势:
1. 避免冗余静态显存:无需维护权重副本,显存更优。2. 流程更简洁:前向开始前执行AllGather获取完整权重,反向结束后释放。
PyTorch 最新原生并行库Titan的FSDP方案也采用了类似设计,说明该思路已成趋势。
本次在杭州举办的昇思人工智能框架峰会。将会邀请思想领袖、专家学者、企业领军人物及明星开发者等产学研用代表,共探技术发展趋势、分享创新成果与实践经验。欢迎各界精英共赴前沿之约,携手打造开放、协同、可持续的人工智能框架新生态!

本文属于原创文章,如若转载,请注明来源:昇思人工智能框架峰会 | 昇思MindSpore优化器并行、Zero还是FSDP?https://news.zol.com.cn/1096/10969014.html