在AI技术高速发展的今天,「让机器真正理解世界」的需求从未如此迫切。无论是电商平台的跨模态搜索、智能助手的多轮对话,还是内容平台的精准推荐,底层都依赖一个关键能力——将文本、图像、视频等不同形态的信息,转化为计算机可理解的「向量」,并通过向量间的关联实现高效匹配与检索。
6月24日,火山引擎发布全模态向量化模型Seed1.6-Embedding,通过三大核心突破,重塑向量化能力边界:不仅在权威测评榜单中包揽中文文本、多模态全面任务的SOTA成绩,更首次实现「文本+图像+视频」混合模态的融合检索,并通过自定义指令能力大幅降低业务落地门槛。
从“单模态支持”到“全任务领先”:Seed1.6-Embedding的技术实力
针对行业对多模态深度理解和高效检索的双重需求,团队采用文本继续训练-多模态继续训练-精调的多阶段训练策略,基于海量文本、图文对、视频文对数据,构建多任务数据集,通过指令引导、数据合成、数据增强、分层负样本等混合训练,提升细分场景和复杂任务处理能力,让其成为覆盖全场景的向量化“全能选手”。
全面任务领先:包揽中文文本、图像、视频「三冠」
在最能体现模型泛化能力的权威榜单中,Seed1.6-Embedding均展现出显著优势:
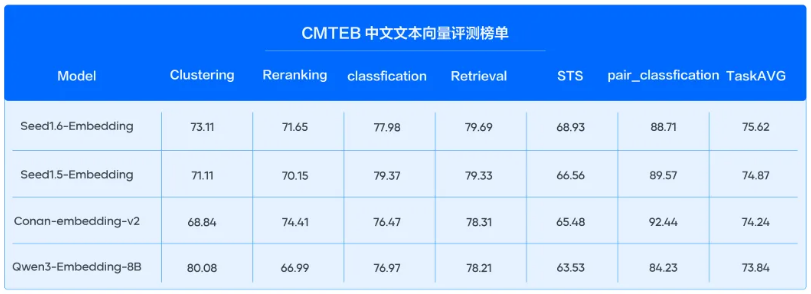
纯文本任务:在CMTEB中文文本向量评测榜单上,模型以75.62高分刷新榜单SOTA,在检索、分类、语义匹配等通用任务表现持续领跑;
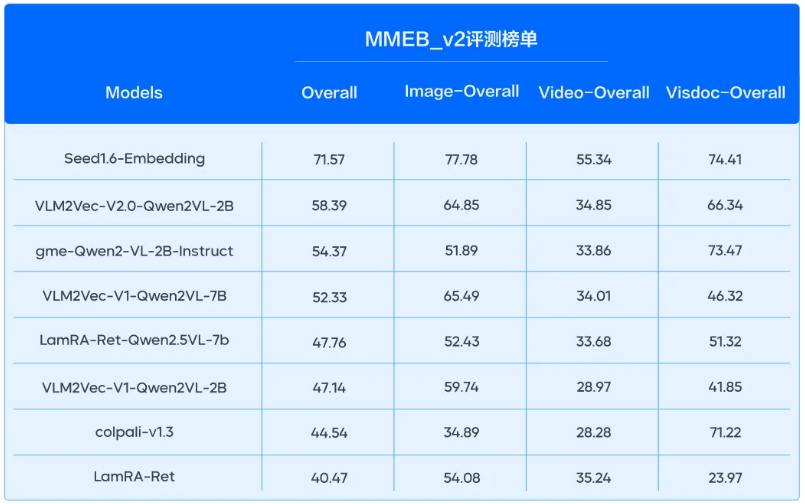
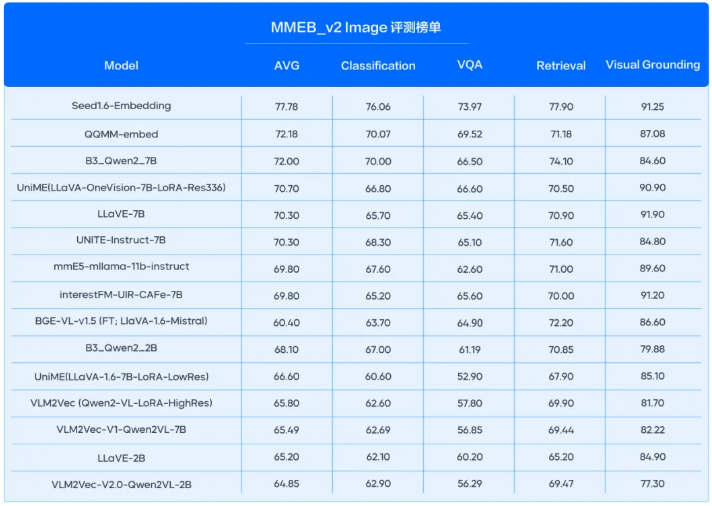
多模态任务:在多模态评测榜单MMEB_v2中,模型的图片、视频向量化任务双双登顶SOTA,并实现断层领先。其中在MMEB_v2Image 榜单上,模型以77.78的高分领先第二名5.6分;模型新增的视频模态,在MMEB_v2video 榜单大幅领先第二名20.1分。
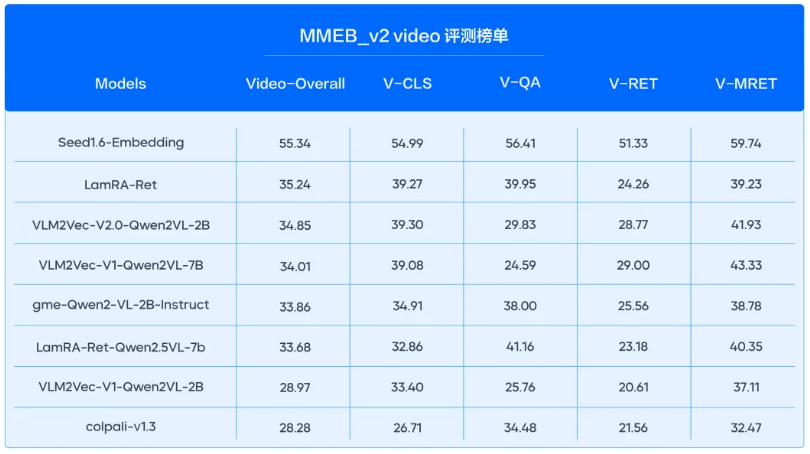

全模态混合检索:支持“文+图+视频”统一向量空间表征
过去,多模态向量化模型往往局限于单模态输入-单模态输出的模式,而真实场景中,用户需求通常是通过混合搜索如文搜图和视频、文图搜视频等方式来精准检索目标内容。Seed1.6-Embedding突破单一搜索限制:
新增视频向量化能力:支持对人物、动作、场景等视频核心语义的统一表征;
全模态混合检索:支持文本、图像、视频等多形态输入的混合表征,输出的向量能同时保留不同模态的关键特征,真正实现「跨模态搜索无界」。
自定义指令增强:让向量生成“按需而变”
业务落地中,不同场景对向量的关注点往往不同:电商需要突出商品的价格、材质等,新闻平台需要强调事件时间、情感倾向。过去,企业常需投入大量标注数据微调模型,成本高、周期长。
Seed1.6-Embedding通过指令增强技术,让向量生成更“听话”:用户只需通过定制化指令模板,就能像给模型下任务清单一样,精准引导向量生成更贴合业务目标的表达。这一能力让模型适配新场景从“重训练”变为“轻调整”,低成本支持电商精准推荐、知识问答等多样化需求,实现一模型多场景,灵活随需而变。
从“技术突破”到“场景落地”:火山方舟让能力「触手可得」
好的模型,最终要服务于真实场景。为了让Seed1.6-Embedding更快、更省心地服务于实际业务需求,火山方舟同步推出两大支持入口:
火山方舟API接口:模型已上线火山方舟控制台,专业开发者可直接调用API,无需自建模型训练与部署环境,即可快速接入业务场景;
VikingDB向量数据库:火山方舟旗下VikingDB向量数据库已深度集成Seed1.6-Embedding模型,提供“向量生成+存储+检索”的一站式解决方案,企业无需额外开发,开箱即用。
未来,团队将继续深耕向量化技术。预计2025年下半年,用户可在火山方舟体验中心实现可视化体验和多模态检索,VikingDB向量数据库也将支持全模态数据自动向量化,并开放图文和视频检索开源项目,助力企业和开发者快速集成到业务场景。火山引擎也将以更开放的姿态,携手企业与开发者,共同探索“让 AI理解世界”的更多可能。