DeepSeek在人工智能领域掀起一场革命性的变革,为行业带来了深远影响。AI正从“大力出奇迹”进化到“巧力出奇迹”,以更高效、更智能的方式推动技术发展。为了满足企业对私有化、国产化部署的需求,昆仑技术与硅基流动紧密合作,凭借双方在AI领域的深厚技术积累和丰富行业经验,正式推出DeepSeek一体机。
实测数据显示,此次推出的一体机在性能表现上相较于业界同类产品实现了35%以上的显著提升。以DeepSeek-R1-671B满血版为例,其并发量可达256以上,吞吐性能达到2599Tokens/s。此次合作不仅标志着在DeepSeek性能优化上的又一重要进展,也为企业提供“更高效、更安全”的DeepSeek私有化智能基座,让前沿AI能力真正生长于企业机房。

架构图
三大核心优势,打造DeepSeek一体机卓越体验
一、三级技术矩阵,软硬全栈调优
基于“算力调度-推理加速-负载均衡”三级技术矩阵,双方提供从硬件层到模型层的全栈调优方案,实现推理效率与资源利用率的显著提升。
●算子深度优化与异构计算协同:通过NPU与CPU的异构调度和并行计算策略,充分发挥NPU的计算加速优势,对算子进行深度优化,最大化发挥硬件性能,显著提升整体计算效率;
●计算图编译优化和算子融合:通过小算子融合技术,并优化NPU计算流水线,减少内核启动开销和内存搬运;结合整图编译优化,降低任务下发和调度耗时,从而全面提升计算效率;
●INT8量化和MTP优化:采用INT8量化技术,结合对多Token预测(Multi-TokenPrediction,MTP)的深度优化,在保持较高推理精度的同时,将显存占用减少50%,并支持更高并发的推理路数;
●动态批处理(DynamicBatching)与请求调度:通过动态批处理技术(如请求合并、短Token合并等),最大化硬件利用率,降低推理延迟;同时优化请求调度算法,确保高优先级请求能够快速响应。
二、国产算力赋能,全离线私有部署
●基于昇腾AI处理器,搭配硅基流动推理加速引擎SiliconLLM,与DeepSeek全量大模型深度适配,使技术链路实现了100%国产化,且经过超大规模集群的商业验证,确保在大规模部署时的稳定性和高效性;
●一体机支持完全离线环境部署,从根本上杜绝数据泄露风险,广泛适用于金融、政务等诸多对数据安全要求极高的场景。
三、横向线性扩容,纵向一键入云
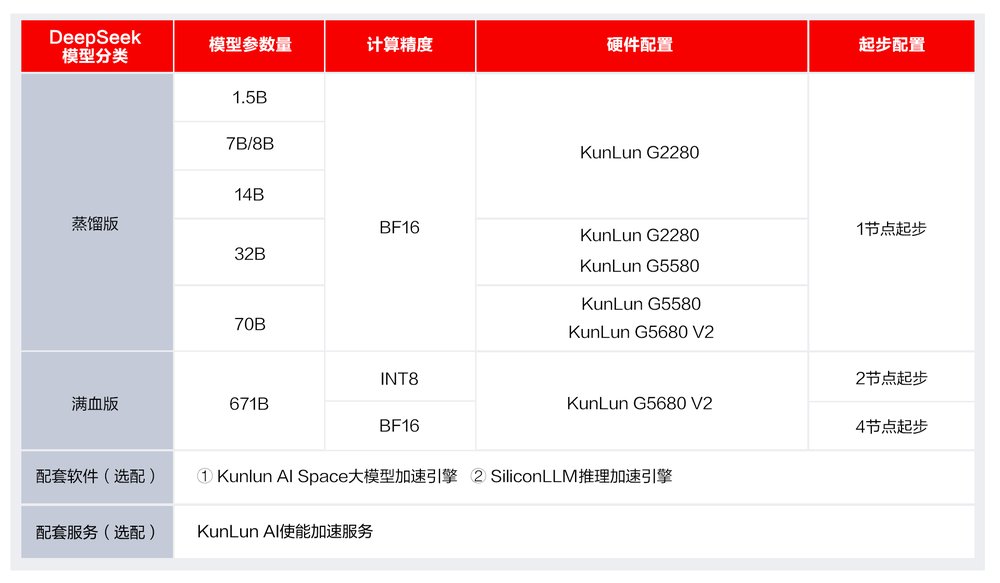
●蒸馏版低至单节点起配,满血版最低两节点起配,可根据业务需求灵活进行线性扩容;
●支持本地化部署硅基流动MaaS平台SiliconCloud,一键接入百种云上大模型服务,如文生图、文生视频、辅助编码等。
DeepSeek一体机推荐配置