4月26日,科大讯飞V3.5发布更新版本,宣布讯飞星火成为业界首个支持长文本、长图文以及长语音的大模型产品。
作为人工智能国家队,科大讯飞此次升级的讯飞星火V3.5,面向用户高效准确知识获取的痛点,不同于行业单“卷”长文本,科大讯飞还为大模型加入了长图文、长语音功能,拓宽了大模型多媒体资料获取和理解的能力。
科大讯飞能为已经稍显降温的长文本注入新的活力吗?长图文和长语音的加入,能打开大模型打开更大的想象空间吗?
用户高效知识获取痛点在哪里?
长文本已经成为国产大模型比拼的新方向。在经过长达一年的对标 ChatGPT-4、比拼参数大小的同质化竞争之后,中国人工智能公司们终于找出了一个更容易被普通用户理解、也更能直观地超越美国同行们的差异化标的。
掀起这一波竞争浪潮的是国内大模型创业公司月之暗面。这家公司在去年将旗下的大模型 Kimi 的上下文参数规模提升至 20 万字,上个月又提升至 200 万,迅速引爆市场。3 月,阿里旗下的通义千问已经将这一数字更新到 1000 万,宣称是“全球文档处理容量第一的 AI 应用”。
华泰证券在一份研报中指出,具有长上下文的大模型通用性更强,用户将特定领域的知识通过上下文的方式输入到模型中,模型即可通过上下文学习掌握相应内容,一定程度上代替模型的微调。
但经过几个月的比拼跟进之后,长文本之于大模型似乎又成了一项厂家炫技的同质化环节,以至于有媒体已经飞快地喊出了“长文本降温”的口号,长文本如何才能真正落地陷入瓶颈。
大模型长文本功能的落地需要重点解决两个问题。一是海量文本的高效处理。面对上百万甚至上千万文字,模型后台消耗的运算资源也成倍增加,业界的一些大模型往往智能处理前 20% 或前 50% 的内容,之后的处理效率就大大减慢。
二是如何保证大模型在科研、医疗、法律等行业专业场景的准确率,这样才能解决大模型在刚需场景的应用问题。
科大讯飞董事长刘庆峰介绍,为了解决大模型应用效率和准确率问题,讯飞星火 V3.5 提升了对长文本的理解、学习、回答能力,并进行了重要的模型剪枝和蒸馏,从而推出业界最优的 130 亿参数的大模型。在效果损失仅 3% 以内的情况下,使得星火在文档上传解析、知识问答的首响时间以及文字生成效率方面都获得了极大的效率提升。
在对比测试中,使用讯飞星火对比国内可测最好的大模型,在保障长文本效果的情况下,无论是10K、64K、128K token,还是更长的文本上,星火大模型的性能都是业界最优。
在准确率上,本次讯飞星火长文本功能全新升级后,具备长文档信息抽取、长文档知识问答、长文档归纳总结、长文档文本生成等能力,总体已经达到GPT-4 Turbo 4月最新长文本版本的97%水平,而在银行、保险、汽车、电力等多个垂直领域的知识问答任务上,讯飞星火长文本总体水平已经超过GPT-4 Turbo。
解决了效率和准确率的问题,长文本才不至于只停留在参数比拼的噱头上,真正落地于应用场景。
除了长文本,为何要加入长图文和长语音
但文本内容只是日常人们获取信息的途径之一。在现实的工作与学习过程中,人们接触的的信息还有大量的图片、语音等多模态信息。只有长文本仍无法完美满足现实社会的需要。
刘庆峰在讯飞星火 V3.5 春季上新的发布会上说,广大用户在知识的获取和学习过程中,往往拿到的资料并不是网上现成的海量长文本,而是随手可见的报刊书籍上的内容。他发出疑问,“能不能用手机一拍就成为我们后台知识的来源?能不能我们参加各种学术研讨会,看到别人的 PPT,上课老师黑板上的板书以及各种同学笔记,都成为我们知识获取和学习的内容?”
目前市面上大多数面向 C 端提供服务的大模型应用都还不支持图文识别。事实上,图文识别一直是多语言大模型的难点之一。
为了解决这一痛点,科大讯飞在多年深耕图文识别的基础上,首发星火图文识别大模型,覆盖了书籍、学术论文、报纸、体检报告、PPT 等 31 个工作生活中的常见场景,并针对最常见的 18 种板面要素进行优化,随手一拍就能向大模型提问,例如页眉、页脚、标题、栏目、段落、表格、插图等要素,甚至还包括比较难但是很实用的公式、印章、二维码、手写材料等。
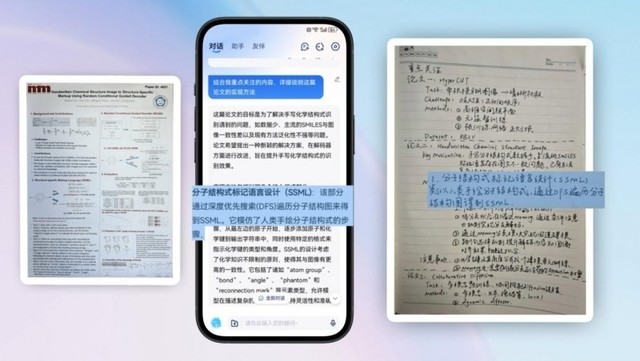
讯飞星火的图文识别能力已经达到国际领先水平。据了解,在英文公开测试集的图文识别效果对比中,星火图文识别大模型已经领先微软、Google 等国际产品。在诸如科研、金融、产品文档等典型应用场景的图文识别效果对比中,星火图文识别大模型均已实现对 GPT-4V 的超越。
在此次升级中,面对广泛的音视频信息高效获取需求,科大讯飞也推出长语音功能,将国际领先的语音识别和翻译技术结合起来,可以实现会议录音、学习视频等的一键研读,实现音视频场景的高效知识获取。语音识别一直是科大讯飞的优势所在,根据IDC 去年年中发布的《中国人工智能软件 2022 年市场份额》报告显示,在人工智能语音语义市场,科大讯飞以 11.4% 的市场份额位居行业第一。在语音识别领域最权威的国际多通道语音分离与识别大赛,科大讯飞连续四届斩获第一,持续领跑国际竞争对手。
刘庆峰介绍,讯飞星火的语音识别不仅仅能针对中文内容进行学习整理,还结合讯飞国际领先的翻译技术,让英文资料也能像纯文字内容一样进行快速获取和学习。
长图文和长语音的加入,为大模型的长文本玩法扩充了更多的想象空间,大模型可以获取的资料不再仅局限于文本内容,视觉、听觉也成为大模型的信息获取来源,可用性与实用性大大加强。
去年,科大讯飞启动了“讯飞超脑 2030 计划”,提出要让具备人工智能的机器人走入每一个家庭中的宏伟愿景。同时兼顾长文本、长图文和长语音能力的讯飞星火,或许就是这个计划的第一步。
在此次讯飞星火V3.5的上新发布中,科大讯飞还宣布将于今年 6 月27日正式推出讯飞星火 V4.0 版本,期待国产大模型的持续进化。
本文属于原创文章,如若转载,请注明来源:长本文、长图文加长语音,国产大模型的内卷新方向?https://news.zol.com.cn/868/8683214.html