01FancyTech技术路径是什么
产品:iPhone 15(128GB) 苹果 手机我们正在见证又一轮技术革新,这一次是AIGC为个体提供表达自我的工具,让创作变得更加容易和普及,但背后的推动力却并不是「大」模型。
两年以来,AIGC技术的发展速度超过所有人的想象,席卷了从文本、图像到视频的各个领域。关于AIGC商业化路径的讨论从来没有停止过,其中,有共识也有路线分化。
一方面,通用模型的强大能力令人惊叹,在各行各业展示出应用潜力。特别是DiT、VAR等架构的提出,让ScalingLaw 实现了从文本到视觉生成领域的跨越。在这一法则的指引下,很多大模型厂商朝着增加训练数据、算力投入和堆积参数的方向持续前进。
另一方面,我们也看到,通用模型并不意味着「通杀」,面对很多细分赛道的任务,一个「训练有素」的垂直模型反而能够取得更好的效果。
随着大模型技术进入落地加速期,后一种商业化路径获得的关注快速增长。
这个演进过程中,一家来自中国的创业公司FancyTech脱颖而出:它以面向商业类视觉内容生成的标准化产品快速拓展市场,比同行们更早一步验证了「垂直模型」在产业落地层面的优越性。
环顾国内大模型创业圈,FancyTech的商业化战绩是有目共睹的。但较少为人所知的是,这家诞生仅几年的公司,凭借怎样的垂直模型和技术优势跑在了赛道前列。
在一次专访中,机器之心和FancyTech聊了聊他们正在做的技术探索。
FancyTech发布视频垂直模型DeepVideo 如何突破行业壁垒?
一般来说,在通用模型的零样本泛化能力达到某个水准后,在其之上做微调就可用于下游任务。这也是当下很多大模型产品落地的打法。但从实际效果来看,仅仅是「微调」还不能满足产业应用需求,因为各个行业的内容生成任务都有自己的特定而复杂的一套标准。
通用模型或许能完成好70%的常规任务,但客户真正需要的是能100%满足需求的「垂直模型」。以商业视觉设计为例,以往的相关工作均由有长期积累的专业人士完成,且需要根据品牌方的具体需求进行设计和调整,其中涵盖大量的人工经验。比起美观度和指令遵循程度等指标,「商品还原度」是这项任务中品牌方更为重视的一点,也是品牌方是否愿意付费的决定因素。
在自研面向商业图像/视频的垂直模型过程中,FancyTech将核心挑战拆解开来:如何让商品足够还原且融入背景,特别是在生成视频中,实现商品的运动可控且不形变。


大模型技术发展到今天,对于应用层来说,走开源或闭源的路线已经不是最核心的问题。FancyTech的垂直模型基于开源的底层算法框架,叠加自有的数据标注重新训练,仅需几百张GPU持续训练迭代即可取得好的生成效果。相比之下,「商品数据」和「训练方式」这两个因素对于最终的落地效果更为关键。
FancyTech在积累海量3D训练数据的前提下,引入了空间智能的思路指导模型的2D内容生成。具体来说,在图像类内容生成上,团队提出「多模态特征器」保证商品的还原,以特殊的数据采集保证商品与背景的自然融合;在视频类内容生成上,团队重建了视频生成的底层链路,定向地设计框架和进行数据工程,从而实现以商品为核心的视频生成。
真•降维打击:「空间智能」如何指导2D内容生成?
很多视觉生成类产品的效果之所以不尽如人意,核心原因就在于目前的图像和视频生成模型往往基于2D训练数据进行学习,并没有理解真正的物理世界。
这一点在领域内已形成共识,部分研究者甚至认为,在自回归学习范式下,模型对世界的理解始终处于浅层。
但在商业视觉生成这项细分任务上,要想增强模型3D物理世界的理解、更好地生成2D内容,并非完全无解。
FancyTech将「空间智能」领域的研究思路迁移到了视觉生成模型的构建中。与一般生成式模型不同,空间智能的思路是从大量传感器获取的原始信号中学习,对传感器获取的原始信号进行精确标定,以赋予模型感知和理解现实世界的能力。
因此,FancyTech以激光雷达扫描替代传统摄影棚拍摄,积累了大量的体现商品融入前后差异的高质量3D数据对,并将3D点云数据与2D数据结合起来共同作为模型训练数据,增强模型对现实世界的理解。
我们知道,在任何视觉内容的生成中,光影效果的塑造都是极具挑战性的任务。光照、发光体、逆光、光斑等元素能够让画面的空间层次感更强,但这对于生成式模型来说是个很难理解的「知识点」。
为了收集尽可能多的自然光影数据,FancyTech在每个环境中建立了数十盏亮度和色温均可调节的灯,意味着海量数据中的每一对都可以叠加多盏灯及不同亮度和色温的变化。

这种高强度的数据收集模拟了真实拍摄场景的灯光,使其更加符合电商场景的特点。

结合高质量的3D数据积累,FancyTech在算法框架上进行了一系列创新,将空间算法与图像、视频算法有机结合,让模型更好地理解核心物体与环境的交互。
在训练过程中,模型可以在一定程度上「涌现」出对物理世界的理解,对三维空间、深度、光的反射和折射,以及光在不同介质、不同材质中运行的结果都有更深的认知,最终实现了生成结果中商品的「强还原」和「超融合」。
「强还原」和「超融合」背后,有哪些算法创新?
面向常见的商品场景图像生成任务,现阶段的主流方法主要用贴图的方式保证商品部分的还原度,然后基于Inpainting技术实现图片场景的编辑。用户选定需要改动的区域,输入Prompt或者提供参考图像,以引导商品场景生成。这种方法的融合效果较好,缺点是场景生成结果的可控性不高,比如不够清晰或者过于简单,保证不了单次输出的高可用率。
针对当前方法无法解决的问题,FancyTech提出了一种自有的「多模态特征器」,在多种维度上提取商品特征,然后使用这些特征生成融入后的场景图。
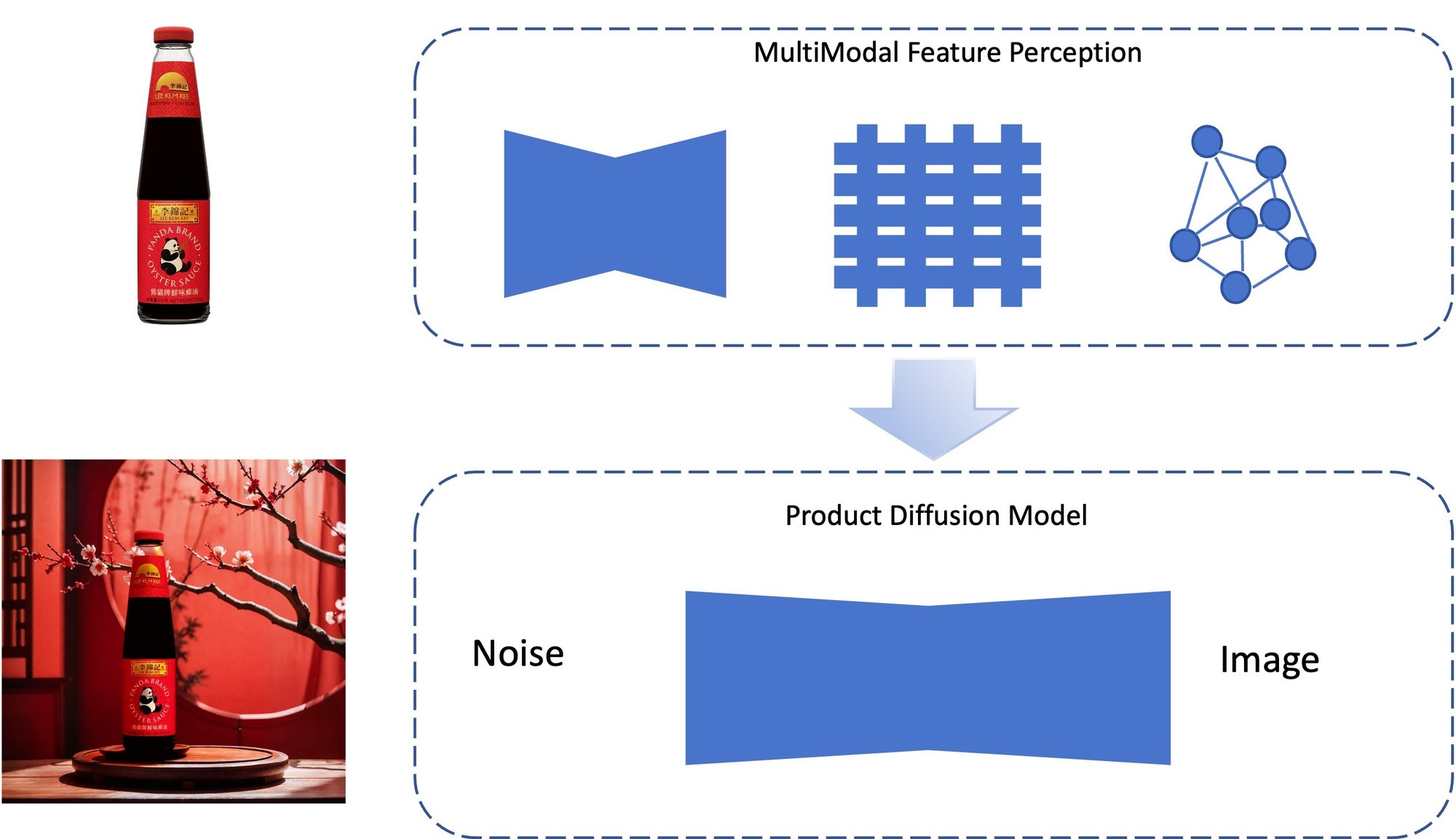
提取特征的工作可分为「全局特征」和「局部特征」,全局特征包括商品的轮廓、颜色等要素,使用VAE编码器提取;局部特征包括各处商品细节,使用图神经网络提取。图神经网络的一大好处是可以提取商品中各关键像素的信息以及关键像素间的关系,提高对于商品内部的细节还原。
在柔性材质商品的内容生成中,这种方法获得的效果提升显著:
相比于图像,视频的生成还涉及商品本身的运动控制及其带来的光影变化。对于通用的视频生成模型来说,难点在于无法针对视频中的某个部分进行独立保护。为了解决这个问题,FancyTech将任务拆解为「商品运动生成」和「视频场景融入」两条支线。
第一步,FancyTech 设计了一些针对性的运动规划方案,以控制商品在画面中的运动,相当于预先「定住」商品在视频每一帧的画面;
第二步,通过控制模块实现视频可控生成。控制模块采用了灵活的设计,可兼容 U-net、DiT 等不同架构,便于扩展优化。
在数据层面,除了使用FancyTech的特有商品数据资源以提供控制训练和商品保护之外,还加入了多个开源数据集以保证场景泛化能力。训练方案结合了对比学习、课程学习,最终实现了对于商品的保护效果。
让AIGC时代的红利 从垂直模型开始走向更多普通人
无论是「通用」还是「垂直」,两条路线的终点都是商业化问题。
FancyTech垂直模型落地最直接的受益者是品牌方,以往,从策划、拍摄、剪辑,一段广告视频的制作周期可能长达几个星期。但在AIGC时代,创作这样一段广告视频只需要十几分钟而已,成本甚至也只需要原来的五分之一。
凭借着海量独有数据和行业Know-how的优势,FancyTech通过垂直模型的优势赢得国内外广泛的认可,与韩国合作伙伴携手签约了三星和LG;与东南亚的知名电商平台Lazada开启合作;在美国,受到了Kate Sommerville 和Solawave等本土品牌的青睐;在欧洲,荣获了LVMH创新大奖,并与欧洲客户深入合作中。
在核心的垂直模型之外,FancyTech还提供了AI短视频全链路自动发布和数据反馈的能力,驱动商品销售持续增长。
更重要的一点是,垂直模型让普通大众利用AIGC技术提高生产力的路径具像化了。比如,一个街边传统照相馆在不增加专业设备和专业人员的情况下,借助FancyTech的产品,即可完成从简单人像拍摄到专业级商业视觉素材制作的业务转型。
现在只要拿起手机,几乎每个人都能拍视频、录音乐,并与全世界分享他们的创作。想象一个AIGC再一次释放个人创造力的未来——
让普通人跨越专业门槛,更轻松地将创意化为现实,从而让每个行业的生产力实现飞跃,并产生更多的新兴产业,AIGC技术带来的时代红利,从这一刻起开始真正走向普通人。
文章来源:机器之心