摘要:昇思已支持在昇腾集群上训练和推理DeepSeek-V3671B
近日,基于昇腾AI硬件与昇思MindSporeAI框架版本的DeepSeek-V3完成开发支持并上线昇思开源社区,面向开发者提供开箱即用的预训练和推理能力,并已成功在大规模集群上预训练和部署。
应用昇思MindSpore大模型使能套件,依托昇思多维混合分布式能力、自动并行、Dryrun集群内存仿真等技术,天级快速适配DeepSeekV3新增模型结构和分布式并行训练能力。同时,昇思MindSpore通过深度优化MLA、DeepSeekMoE等网络结构的推理,实现了
当前,通过获取昇思MindSpore版DeepSeekV3开源镜像,开发者可直接进行DeepSeek-V3的预训练和推理部署。
开源链接
昇思MindSpore开源社区训练代码:
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
魔乐社区推理代码:
https://modelers.cn/models/MindSpore-Lab/DeepSeek-V3
以下是完整的手把手教程,助力开发者开箱即用
【预训练开箱流程】
MindSporeTransformers支持对DeepSeek-V3进行预训练。仓库中提供了一份预训练配置文件供参考,该配置基于128台Atlas800T A2 (64G),使用Wikitext-2数据集进行预训练,可参考多机教程进行使用:
https://gitee.com/mindspore/mindformers/tree/dev/research/deepseek3
便于开发者上手体验,本章节基于此配置进行修改,缩小了DeepSeek-V3模型参数量,使其能够在单台Atlas800T A2 (64G)上拉起预训练流程。
一、环境介绍
准备一台Atlas800T A2 (64G)训练服务器。MindSporeTransformers的环境依赖如下:
提供了DeepSeek-V3预训练专用Docker镜像,通过如下步骤进行使用。
1.下载Docker镜像
使用如下命令下载DeepSeek-V3预训练专用镜像:
dockerpullswr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209
2.基于镜像创建容器
使用如下命令新建容器:
image_name=swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.4.10-train:20250209
docker_name=deepseek_v3
dockerrun -itd -u root \
--ipc=host--net=host \
--privileged\
--device=/dev/davinci0\
--device=/dev/davinci1\
--device=/dev/davinci2\
--device=/dev/davinci3\
--device=/dev/davinci4\
--device=/dev/davinci5\
--device=/dev/davinci6\
--device=/dev/davinci7\
--device=/dev/davinci_manager\
--device=/dev/devmm_svm\
--device=/dev/hisi_hdc\
-v/etc/localtime:/etc/localtime \
-v/usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v/usr/local/Ascend/driver/tools/hccn_tool:/usr/local/bin/hccn_tool \
-v/etc/ascend_install.info:/etc/ascend_install.info \
-v/var/log/npu:/usr/slog \
-v/usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v/etc/hccn.conf:/etc/hccn.conf \
--name"\$docker_name" \
"\$image_name"\
/bin/bash
3.进入容器
使用如下命令进入容器,并进入代码目录:
dockerexec -ti deepseek_v3 bash
cd/home/work/mindformers
二、数据集准备
以Wikitext-2数据集为例,参考如下步骤将数据集处理成MegatronBIN式文件。
1.下载数据集和分词模型文件
○数据集下载:WikiText2数据集
https://ascend-repo-modelzoo.obs.cn-east-2.myhuaweicloud.com/MindFormers/dataset/wikitext-2/wikitext-2-v1.zip
○分词模型下载:DeepSeek-V3的tokenizer.json
https://huggingface.co/deepseek-ai/DeepSeek-V3/resolve/main/tokenizer.json?download=true
2.生成MegatronBIN格式文件
将数据集文件wiki.train.tokens和分词模型文件tokenizer.json放置在/home/work/dataset下
使用以下命令转换数据集文件
cd/home/work/mindformers/research/deepseek3
pythonwikitext_to_bin.py \
--input/home/work/dataset/wiki.train.tokens \
--output-prefix/home/work/dataset/wiki_4096 \
--vocab-file/home/work/dataset/tokenizer.json \
--seq-length4096 \
--worker1
三、单机配置样例
基于预训练配置文件pretrain_deepseek3_671b.yaml按照如下步骤操作并保存为pretrain_deepseek3_1b.yaml。
1.修改模型配置
#model config
model:
model_config:
type: DeepseekV3Config
auto_register: deepseek3_config.DeepseekV3Config
seq_length: 4096
hidden_size: 2048 #修改为2048
num_layers: &num_layers3 #修改为3
num_heads: 8 #修改为8
max_position_embeddings: 4096
intermediate_size: 6144 #修改为6144
offset: 0 #修改为0
……
2.修改MoE配置
#moe
moe_config:
expert_num: &expert_num16 #修改为16
first_k_dense_replace: 1 # 修改为1
……
3.修改并行配置
#parallel config for devices num=8
parallel_config:
data_parallel: 2 #修改为2
model_parallel: 2 #修改为2
pipeline_stage: 2 #修改为2
expert_parallel: 2 #修改为2
micro_batch_num: µ_batch_num4 #修改为4
parallel:
parallel_optimizer_config:
optimizer_weight_shard_size:8 #修改为8
……
4.修改学习率配置
#lr schedule
lr_schedule:
type:ConstantWarmUpLR
warmup_steps:20 #修改为20
5.修改数据集配置
配置数据集路径:
#dataset
train_dataset: &train_dataset
data_loader:
type: BlendedMegatronDatasetDataLoader
config:
data_path:
-1
-"/home/work/dataset/wiki_4096_text_document" #修改此项为数据集路径
……
配置数据集并行通信配置路径:
#mindspore context init config
context:
ascend_config:
parallel_speed_up_json_path:
"/home/work/mindformers/research/deepseek3/parallel_speed_up.json" # 修改此项为数据集并行通信配置路径
四、拉起任务
进入代码根目录并执行以下命令拉起单台Atlas800T A2(64G)预训练任务:
cd/home/work/mindformers
bashscripts/msrun_launcher.sh "run_mindformer.py \
--register_pathresearch/deepseek3 \
--configresearch/deepseek3/deepseek3_671b/pretrain_deepseek3_1b.yaml"
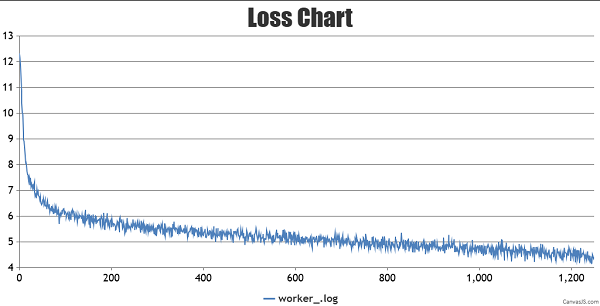
启动脚本执行完毕会在后台拉起任务,日志保存在/home/work/mindformers/output/msrun_log下,使用以下命令查看训练日志(由于开启了流水并行pipeline_stage:2,loss只显示在最后一张卡的日志worker_7.log中,其他日志显示loss为0):
tail-f /home/work/mindformers/output/msrun_log/worker_7.log
训练loss的曲线图如下
训练过程中的权重checkpoint将会保存在/home/work/mindformers/output/checkpoint下。
【推理部署开箱流程】
采用BF16格式的模型权重文件,运行DeepSeek-V3推理服务,需要4台Atlas800IA2(64G)服务器。为缩短开发部署周期,昇思MindSpore此次提供了docker容器镜像,供开发者快速体验。其主要操作步骤如下:
●执行以下Shell命令,下载昇思MindSporeDeepSeek-V3推理容器镜像:
dockerpull
swr.cn-central-221.ovaijisuan.com/mindformers/deepseek_v3_mindspore2.5.0-infer:20250209
●执行以下Shell命令,启动容器镜像,后续操作将均在容器内进行:
dockerrun -itd --privileged --name=deepseek-v3 --net=host \
--shm-size500g \
--device=/dev/davinci0\
--device=/dev/davinci1\
--device=/dev/davinci2\
--device=/dev/davinci3\
--device=/dev/davinci4\
--device=/dev/davinci5\
--device=/dev/davinci6\
--device=/dev/davinci7\
--device=/dev/davinci_manager\
--device=/dev/hisi_hdc\
--device/dev/devmm_svm \
-v/usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v/usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v/usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v/usr/local/sbin:/usr/local/sbin \
-v/etc/hccn.conf:/etc/hccn.conf \
deepseek_v3_mindspore2.5.0-infer:20250209\
bash
●执行以下Shell命令,将用于下载存储DeepSeek-V3权重文件的路径(开箱示例中为./model_path),添加至白名单:
exportHUB_WHITE_LIST_PATHS=./model_path
●使用以下Python脚本,从魔乐社区下载昇思MindSpore版本的DeepSeek-V3权重文件至指定路径。完整的权重文件约1.4TB,请确保指定路径下有充足的可用磁盘空间:
fromopenmind_hub import snapshot_download
snapshot_download(
repo_,
local_dir="./model_path",
local_dir_use_symlink=False
)
●将./model_path/examples/predict_deepseek3_671B.yaml文件中的load_checkpoint参数配置为权重文件夹
●在第1台至第4台服务器上,分别执行以下Shell命令,通过msrun_launcher.sh启动单次推理测试脚本run_deepseekv3_predict.py,完成后将显示“生抽和老抽的区别是什么?”的问题回复。其中,master_ip需修改设置为第1台服务器的实际IP地址。
#第1台服务器(Node0)
exportPYTHONPATH=/root/mindformers/:\$PYTHONPATH
exportHCCL_OP_EXPANSION_MODE=AIV
exportMS_ENABLE_LCCL=off
master_ip=192.168.1.1
cdmodel_path/DeepSeek-V3/examples
bashmsrun_launcher.sh "run_deepseekv3_predict.py" 32 8\$master_ip 8888 0
output/msrun_logFalse 300
#第2台服务器(Node1)
exportPYTHONPATH=/root/mindformers/:\$PYTHONPATH
exportHCCL_OP_EXPANSION_MODE=AIV
exportMS_ENABLE_LCCL=off
master_ip=192.168.1.1
cdmodel_path/DeepSeek-V3/examples
bashmsrun_launcher.sh "run_deepseekv3_predict.py" 32 8\$master_ip 8888 1
output/msrun_logFalse 300
#第3台服务器(Node2)
exportPYTHONPATH=/root/mindformers/:\$PYTHONPATH
exportHCCL_OP_EXPANSION_MODE=AIVexport MS_ENABLE_LCCL=off
master_ip=192.168.1.1
cdmodel_path/DeepSeek-V3/examples
bashmsrun_launcher.sh "run_deepseekv3_predict.py" 32 8\$master_ip 8888 2 output/msrun_log False 300
#第4台服务器(Node3)
exportPYTHONPATH=/root/mindformers/:\$PYTHONPATH
exportHCCL_OP_EXPANSION_MODE=AIV
exportMS_ENABLE_LCCL=off
master_ip=192.168.1.1
cdmodel_path/DeepSeek-V3/examples
bashmsrun_launcher.sh "run_deepseekv3_predict.py" 32 8\$master_ip 8888 3
output/msrun_logFalse 300
●此外,还可参考魔乐社区MindSpore-Lab/DeepSeek-V3模型仓的ReadMe指引,进行推理服务化部署,然后通过访问与OpenAI兼容的RESTful服务端口,体验多轮对话服务。
1.MindSpore支持DeepSeek V3增量模块的快速开发
DeepSeek V3的关键网络结构的支持:
●MTP:在MTP模块中,MindSpore通过shard()接口对MTP入口处的激活融合结构配置了序列并行,消除不必要的通讯重排。通过set_pipeline_stage()接口实现了embedding矩阵在first_stage和last_stage间的参数共享,即由first_stage负责维护embedding的参数更新,训练前向时发送给last_stage,训练反向时从last_stage回收梯度。
●AuxFree Balance:MindSpore的MoE模块中已支持全局的Expert负载统计,AuxFree Balance机制的实现是在callback中新增了根据全局专家负载而更新专家偏置的逻辑,从而达到在每个trainstep结束后做一次负载均衡调整的目的。
●MoE Sigmoid激活:在Routerscore后的激活函数部分新增了可配置项,用户可以通过yaml文件灵活选择softmax或sigmoid作为激活函数,支持开发者灵活选择。
2.MindSpore对于DeepSeek V3推理网络的实现和优化
MindSpore针对DeepSeekV3的网络结构特点,
●MLA:将FC、MatMul等超过10个小算子,融合成单个InferAttention-MLA算子,然后将其与已有的PageAttention算子,组合实现MLA模块功能。同时,在InferAttention-MLA算子内,设计了Key-Value张量存储复用机制,减少存储资源占用。
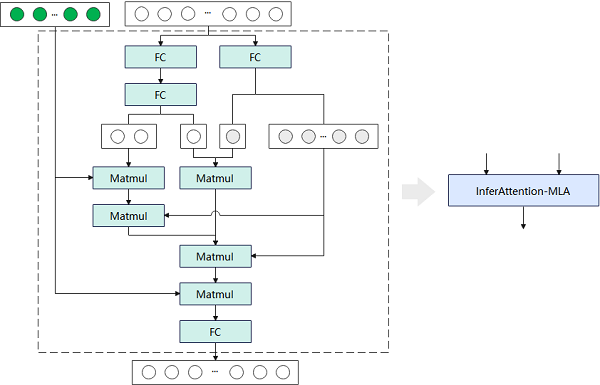
图1MLA推理网络实现原理
●DeepSeekMoE:MindSpore优化精简了MoE的推理代码实现,并新增实现MoeUnpermuteToken、MoeInitRouting等多个融合大算子,用于组合实现DeepSeek-V3的MoE单元,降低了单个MoE单元的推理时延。
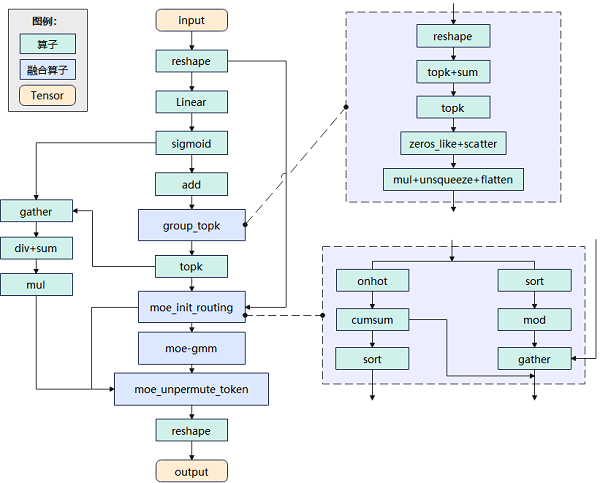
图2DeepSeekMoE推理网络实现原理
●图编译:MindSpore推理使用了图编译进行加速,通过对整图进行Pattern匹配,无需修改模型脚本,即可实现整图的通用融合。以DeepSeekV3为例,在图编译过程中实现了Add+RmsNorm、SplitWithSize+SiLU+Mul等众多Pattern的自动融合。
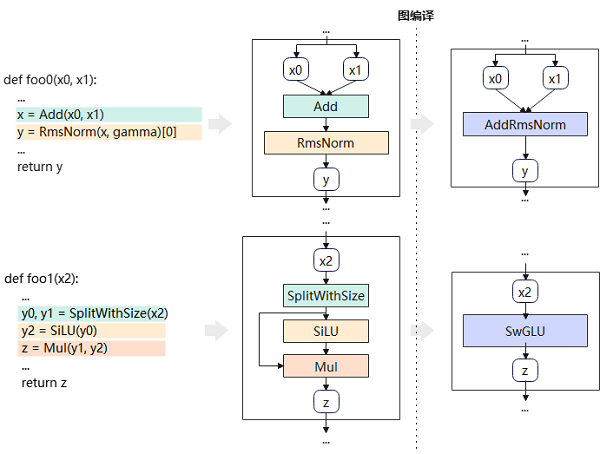
图3图编译原理
3.MindSpore框架特性助力DeepSeek V3训练性能提升
DeepSeekV3的训推适配过程中,通过MindSpore的MoE模块优化、Dryrun仿真等技术,在优化MoE的训练流程的同时,还实现了更
●MoE模块优化:在MoE模块中可支持多种主流结构可配置,如共享专家、路由专家个数、激活函数选择等,极大地提升了模型的灵活性。在MoE并行方面支持TP-extend-EP、路由序列并行、MoE计算通讯掩盖、分组AllToAll通讯等多种并行模式和并行优化,用户可在配置中更灵活地使用相关并行加速能力。
●Dryrun集群内存仿真与自动负载均衡:MindSpore的Dryrun工具可以根据训练任务模拟出集群中每卡的内存占用情况,从而在不实际占用集群的情况下,为训练的分布式并行策略调优提供快捷反馈。自动负载均衡工具SAPP为DeepSeekV3通过
下一步,昇思MindSpore开源社区将上线DeepSeekV3微调样例与R1版本镜像,为开发者提供开箱即用的模型。未来,昇思开源社区将依托丰富的技术能力,持续优化DeepSeekV3系列模型的性能,加速模型从训练到生产部署端到端的创新效率,为开源开发者进行大模型创新提供了
在使用模型中,有任何疑问和建议,均可通过社区进行反馈。
昇思MindSpore开源社区DeepSeekV3使用问题讨论issue:
https://gitee.com/mindspore/mindformers/issues/IBL0X5?from=project-issue
昇腾社区昇思论坛DeepSeekV3使用问题讨论帖:
https://www.hiascend.com/forum/thread-02112174450796469017-1-1.html