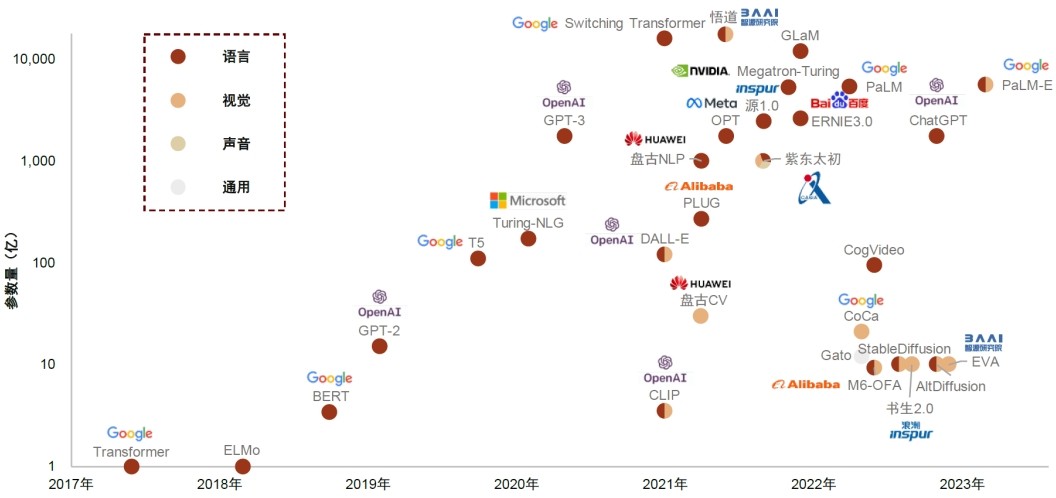
伴随着智算技术的发展,越来越多的研究表明在AI训练达到一定规模下能力才会涌现,在AI大模型的扩展定律和涌现能力的驱动下,AI大模型的参数规模越来越大。国内外业界已出现多个万亿参数模型,十万亿参数模型在不远的将来也有望问世。公开资料表明,GPT-4的参数体量比GPT-3增长了10倍,达到1.8万亿参数。国内的盘古、悟道大模型,其参数规模同样超过了万亿。
注:数据截至23年3月,资料来源:北京智源人工智能研究院,中金公司研究院
美国当地时间7月22日,特斯拉CEO埃隆·马斯克在旗下社交平台X上表示,xAI团队、X团队、英伟达及其他支持公司已经于当地时间凌晨4时20分开始在“孟菲斯超级集群(MemphisSupercluster)”上进行训练。“孟菲斯超级集群”由10万个液冷H100GPU组成,在单个RDMA结构上运行,是“
大规模智算集群需要高性能的网络连接,以保证各智算节点间的通信效率、数据吞吐和整个智算集群的算力性能。这对智算网络提出了新的挑战。
在基础训练模型中,一方面多任务混合部署,传统以太网源端发流直接采用网络“Push”流量模式,不考虑网络及接收端的接受能力,导致网络拥塞,使得GPU处于等待状态,造成梯度和参数同步过程中算力资源浪费较大,传统的RoCE网络有效吞吐仅为50%;另一方面,智算集群网络流量呈现出数据流数目少、单流流量大的特点,在传统网络均衡算法下容易引发HASH冲突,造成链路丢包,导致训练异常中断,极大影响训练效率。时代呼唤“零丢包”、“高吞吐”、“低时延”为核心特征的无损智算网络设备,来解决超大规模AI计算通信效率低的问题。

当前
流派1:IB(InfiniBand)网络,是目前市场占有率
流派2:RoCE(RDMAover ConvergedEthernet)网络,RoCE广泛应用于需要高带宽和低延迟的网络,在传统的通算领域有很高的占有率,但是RoCE在智算网络中存在流量HASH极化的问题,需要辅助以各种均衡调参进行智算网络的适配。
为了更好的提升智算网络性能,更好的服务于大规模AI计算,出现了更多的新型技术流派:
新技术流派1:UEC(UltraEthernet Consortium)网络,2023年7月Linux基金会与
新技术流派2:GSE(GlobalScheduling Ethernet)网络,中国智算中心的建设热潮始于2020年,目前已有40多个城市在建设或在建智算中心。智算中心建设步伐加快,但国内的网络技术发展却滞后于AI大模型的演进。AI网络技术上的竞争已经成为中美技术博弈的新战场。在这样严峻的形势下,2023年5月,中国移动联合产业界发布了全调度以太网(GSE)白皮书,同年8月全调度以太网推进计划正式开启,标志着具有中国自主技术的GSE流派正式诞生。

GSE是一个开放的生态组织,2023年9月,中国移动发布推GSE交换机原型系统样机。2024年1月在移动实验室完成了GSE交换机多厂商设备的互联互通测试。

GSP设备

GSF设备
GSE网络,专为大规模AI训练集群打造:
按需调度,性能无损
GSE网络基于PKTC容器技术,实现了高精度的网络负载均衡,从根本上改善了传统AI算力网络链路的带宽利用率;采用基于DQSQ的信令申请调度技术,数据流以“Pull”的方式进行转发,突破了传统以太网的性能瓶颈,网络性能提升至95%以上。
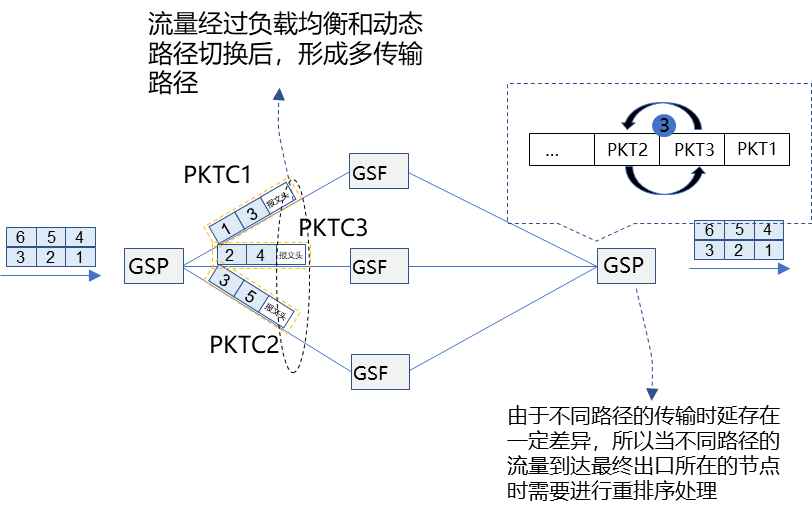
PKTC容器技术
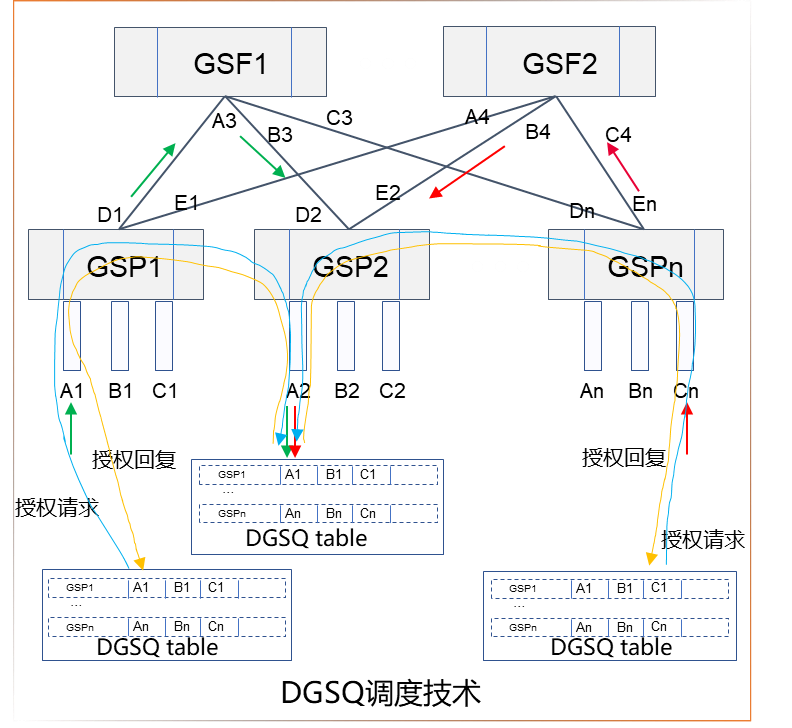
DGSQ调度技术
在多业务部署场景下,相较于传统RoCE网络性能大幅下降,GSE交换机能保持与单业务场景持平的网络转发性能,极大提升网络效率。
场景灵活,快速部署
GSE纯网侧方案即可满足智算无损需求,可搭配国产GPU集成网卡,降低端侧网卡要求。GSE技术原生解决了适配不同大模型训练的网络调参问题,避免了传统RoCE达数天甚至数周的网络参数调优,在算力昂贵、AI大模型竞争激烈的市场中,为客户带来灵活的算力网络建设方案,缩短了训练调优周期,帮助客户快速抢占市场先机。

全局解耦,开放生态
GSE技术体系支持标准以太网标准,新增标准协议头,完成基于以太报文的转发,实现端到端的多厂家设备互联互通,构建了多厂家充分参与的开放生态,全面激活国内AI产业链,促进智算产业创新发展。
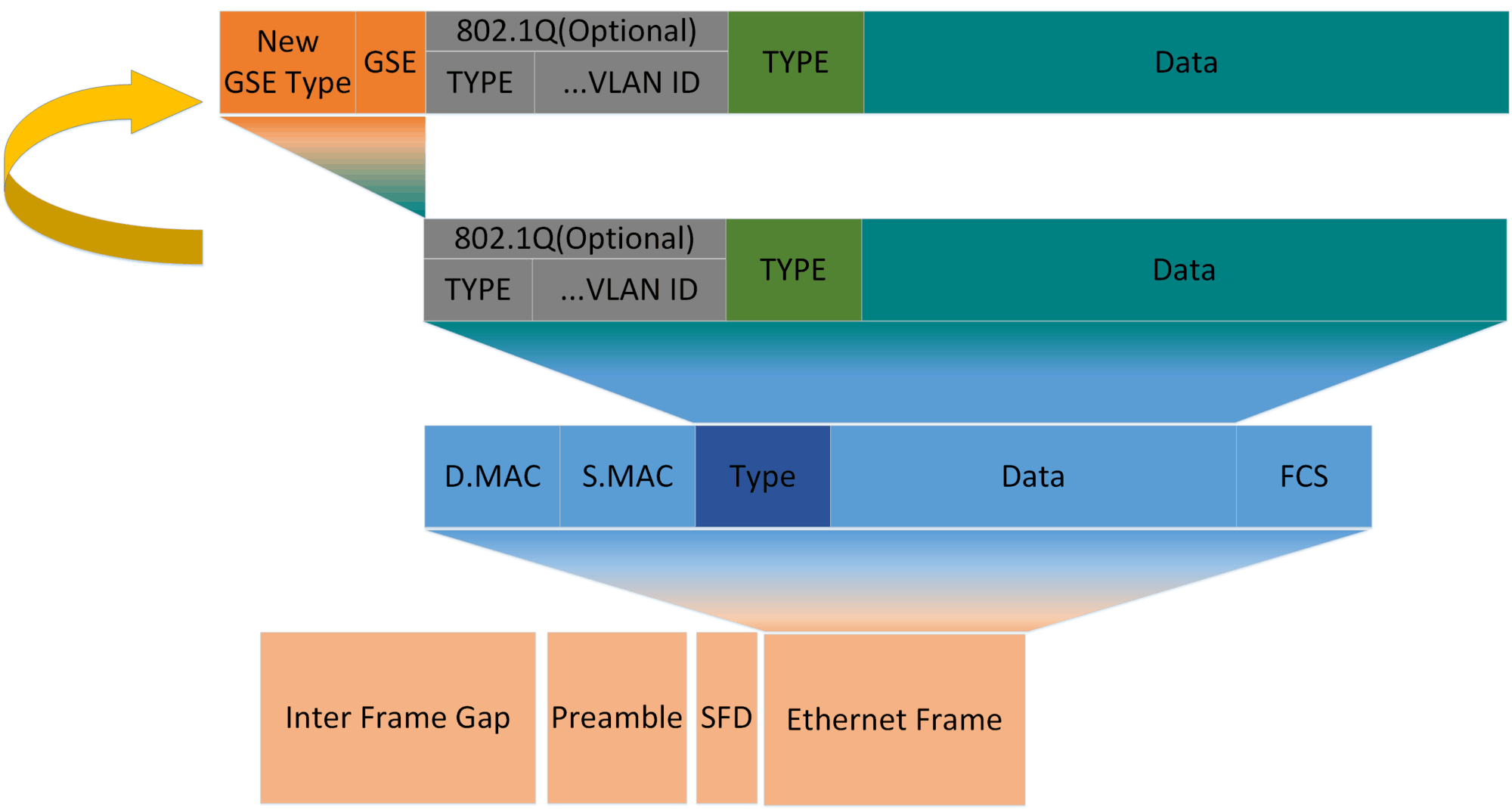
GSE标准协议头
【总结】
锐捷网络致力于与GSE生态一起打造中国的AIGC智算网络新标准。GSE网络设备基于标准以太网在转发架构方面进行技术创新,突破传统以太网的性能瓶颈,拓展智算网络的应用场景,充分满足国产化智算集群网络的需求,为客户带来了三大核心价值:提高智算效率,增强运维体验,开放生态解耦。